Gemma 3 1B Reasoning Fine-Tuning with Tunix (LoRA SFT -> GRPO)
Independent R&D (Google Tunix Hackathon / Kaggle TPU) · Jan 2026 - Present
- Business impact
- 100% strict XML post-repair (40% raw -> 100% repaired)
- Scale
- Kaggle TPU-stable Tunix 0.1.6 pipeline
The Challenge
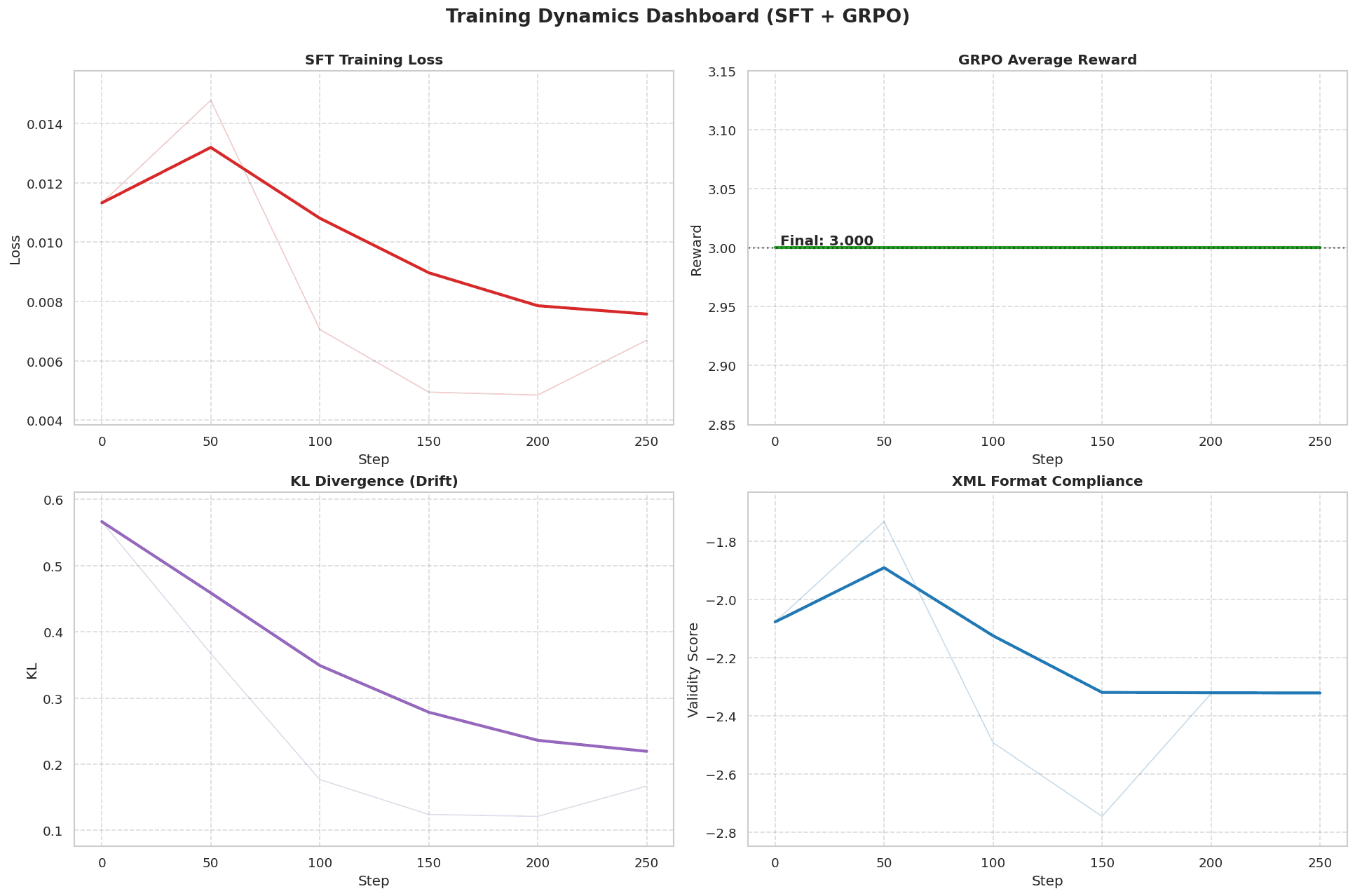
Training had to improve reasoning depth while never violating a strict XML output contract under Kaggle TPU memory and cache constraints. Key failure modes included malformed tags, empty outputs, rollout concat mismatches, and KV-cache sizing errors during generation-heavy GRPO.
The Architecture
Two-stage training stack: Stage 1 LoRA SFT seeds strict XML structure and instruction-following; Stage 2 GRPO applies composite rewards for format validity, task quality, and stability. Inference is wrapped in deterministic strict-XML repair + escaping so judge-facing outputs always satisfy the contract.
The Impact
Delivered a TPU-stable, judge-ready pipeline with deterministic strict-XML compliance. In smoke tests, raw strict XML validity was 40.00% (8/20), deterministic repair raised strict XML to 100.00% (20/20), and normalized repaired math exact match reached 15.00% (3/20).
Discover more
Related ML Systems & Business Impact
Explore adjacent case studies that highlight similar technical depth and measurable outcomes.
Offline Multimodal Clinical Triage Copilot
Outcome: ~10-14 min saved per complex case
Ranking + Recommendations at Scale
Outcome: +10% CTR; +25% Recall@K

Predictive Logistics + Optimization
Outcome: +30% efficiency; +5% backhaul
Ready to turn AI into measurable business impact?
I partner with teams to ship production ML systems, drive revenue lift, and unlock operational efficiency at scale.